I am very often warning: dropping redundant indexes in production is not 100% safe. I have instead always been advocating paying a careful attention during design time to avoid creating redundant indexes. In my professional experience I have realized that, it is very often when creating indexes to cover the lock threat of unindexed foreign key constraints, that developers are creating unintentionally redundant indexes. It has been irritating me so that I have created a script which checks if a given foreign key is already indexed or not before creating supplementary non wanted indexes damaging the DML part of the application.
Having said that I still have not defined what is redundant indexes
“Indexes ind_1 and ind_2 are said redundant when leading columns of one index are a superset of the leading columns of the other one”
For example
Ind_1 (a,b) and ind_2(a,b,c) are redundant because ind_2 contains index ind_1.
If you are at design time it is obvious that you should not create index ind_1. However, once in production, it is not 100% safe to drop index ind_1 without any impact. There are, for sure, occasions were the clustering factor of ind_2 is so dramatic when compared to index ind_1 so that if the later index is dropped the optimizer will opt for a full table scan traumatizing the queries that were perfectly happy with the dropped redundant index.
I can also show you another type of what people might consider redundant indexes while they aren’t. Consider the following model where I have created a range partitioned table (mho_date being the partition key and I have created 1493 partitions) and two indexes as shown below
desc partitioned_tab Name Null? Type ------------------------------- -------- ------------ 1 MHO_ID NOT NULL NUMBER(10) 2 MHO_DATE NOT NULL DATE 3 MHO_CODE NOT NULL VARCHAR2(1) 4 MHO_TYP_ID NOT NULL NUMBER(10) create index local_ind_1 on partitioned_tab (mho_typ_id,mho_code) local; create index global_ind_1 on partitioned_tab (mho_typ_id);
I am going to execute a simple query against the above engineered partitioned table.
select * from partitioned_tab where mho_typ_id = 0;
Which, in the presence of the above two indexes is honored via the following execution plan
----------------------------------------------------------------------
Plan hash value: 3042058313
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows |Cost (%CPU)| Pstart| Pstop |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1493 | 1496 (0)| | |
| 1 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| PARTITIONED_TAB | 1493 | 1496 (0)| ROWID | ROWID |
|* 2 | INDEX RANGE SCAN | GLOBAL_IND_1 | 1493 | 4 (0)| | |
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("MHO_TYP_ID"=0)
Statistics
-------------------------------------------------------
48 recursive calls
0 db block gets
3201 consistent gets
0 physical reads
0 redo size
51244 bytes sent via SQL*Net to client
1632 bytes received via SQL*Net from client
101 SQL*Net roundtrips to/from client
7 sorts (memory)
0 sorts (disk)
1493 rows processed
As you might already know I am one of the fans of SQLT tool developed by Carlos Sierra. And here below what this tool said about redundant indexes in this particular case
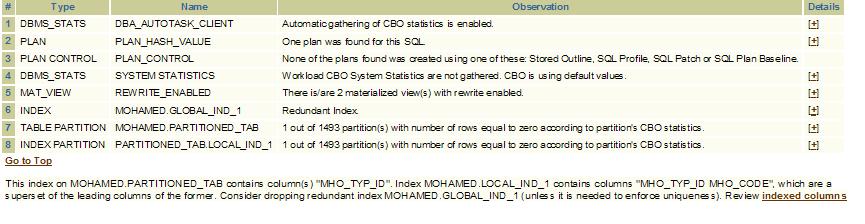
It is clearly suggesting considering dropping the redundant index global_ind_1 index
So let’s follow this advice and see what happens. Hopefully with the recent Oracle release I will first make the index invisible ( by the way that’s a good point to signal for Carlos Sierra and Mauro Pagano for them to suggest setting first the index invisible before considering dropping it)
alter index global_ind_1 invisible;
select * from partitioned_tab where mho_typ_id = 0;
-------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1493 | 23888 | 2985 (1)| | |
| 1 | PARTITION RANGE ALL | | 1493 | 23888 | 2985 (1)| 1 | 1493 |
| 2 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| PARTITIONED_TAB | 1493 | 23888 | 2985 (1)| 1 | 1493 |
|* 3 | INDEX RANGE SCAN | LOCAL_IND_1 | 1493 | | 1492 (0)| 1 | 1493 |
-------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("MHO_TYP_ID"=0)
Statistics
--------------------------------------------------------
48 recursive calls
0 db block gets
4588 consistent gets
0 physical reads
0 redo size
47957 bytes sent via SQL*Net to client
1632 bytes received via SQL*Net from client
101 SQL*Net roundtrips to/from client
7 sorts (memory)
0 sorts (disk)
1493 rows processed
By making the ”redundant” index invisible we went from a smooth one global index range scan with a cost of 4 to 1493 index range scans with a cost of 1492 with an additional 1387 logical reads.
Bottom line: You should always consider dropping (avoiding) redundant index at design time. Once in production consider making them invisible first before thinking carefully about dropping them.
PS : if you want to create the table the script can be found partitioned table

Mohamed,
an additional point: in some cases the optimizer uses the statistics (for example the number of distinct combinations) of an index that seems to be completely useless (or at least unused). Removing this index could also have an unexpected effect on some plans.
Regards
Martin
Comment by Martin Preiss — April 10, 2014 @ 7:28 am |
Hi Martin,
The first time I heard about Oracle using the index to get correct estimations is when reading Richard Foote Oracle11g New Features Presentation (page 18 and 19)
Following your comment, I spent 10 minutes trying to reproduce a case of dropping redundant index that leads to the CBO doing wrong estimations but have not been successful yet
Best regards
Comment by hourim — April 10, 2014 @ 12:12 pm |
Hi Mohamed,
I hope the source code formatting works as I expect …
-- 11.2.0.1 drop table test_ind_selectivity; create table test_ind_selectivity tablespace test_ts as select rownum id , mod(rownum, 10) col1 , mod(rownum, 100) col2 , lpad('*', 100, '*') pad from dual connect by level <= 100000; exec dbms_stats.gather_table_stats(user, 'TEST_IND_SELECTIVITY', method_opt=>'FOR ALL COLUMNS SIZE 1') create index test_ind_selectivity_ix1 on test_ind_selectivity(col1, col2); select /*+ index(test_ind_selectivity) test1 */ count(id) from test_ind_selectivity where col1 = 1 and col2 = 1; COUNT(ID) ---------- 1000 --------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 11 | 1003 (0)| 00:00:06 | | 1 | SORT AGGREGATE | | 1 | 11 | | | | 2 | TABLE ACCESS BY INDEX ROWID| TEST_IND_SELECTIVITY | 1000 | 11000 | 1003 (0)| 00:00:06 | |* 3 | INDEX RANGE SCAN | TEST_IND_SELECTIVITY_IX1 | 1000 | | 3 (0)| 00:00:01 | --------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("COL1"=1 AND "COL2"=1) drop index test_ind_selectivity_ix1; select /*+ index(test_ind_selectivity) test1 */ count(id) from test_ind_selectivity where col1 = 1 and col2 = 1; COUNT(ID) ---------- 1000 ------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 11 | 65 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 11 | | | |* 2 | TABLE ACCESS FULL| TEST_IND_SELECTIVITY | 100 | 1100 | 65 (0)| 00:00:01 | ------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter("COL2"=1 AND "COL1"=1)So with the index statistics the optimizer is able to determine the correlation of the values – and looses the information when the index is dropped. Maybe extended statistics would be more appropriate to give the optimizer the missing information.
Regards
Martin
Comment by Martin Preiss — April 10, 2014 @ 12:32 pm |
Martin,
I was thinking to the issue with the presence of an extra index that makes the TEST_IND_SELECTIVITY_IX1 index redundant and hence candidate for a drop
SQL> create index extra_ind_selectivity on test_ind_selectivity(col1,col2,pad); Index created. SQL> alter index TEST_IND_SELECTIVITY_IX1 invisible; Index altered. SQL> select /*+ index(extra_ind_selectivity) test1 */ count(id) from test_ind_selectivity where col1 = 1 and col2 = 1; COUNT(ID) ---------- 1000 ------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | | | 407 (100)| | | 1 | SORT AGGREGATE | | 1 | 11 | | | | 2 | TABLE ACCESS BY INDEX ROWID| TEST_IND_SELECTIVITY | 1000 | 11000 | 407 (1)| 00:00:02 | |* 3 | INDEX RANGE SCAN | EXTRA_IND_SELECTIVITY | 1000 | | 7 (0)| 00:00:01 | ------------------------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("COL1"=1 AND "COL2"=1)The new index is still helping the CBO to make good estimations. But there might be cases where the new extra index will not be any more of a precious help for the CBO estimations as the original index was. That’s what I still haven’t succeeded to model.
Best Regard
Comment by hourim — April 10, 2014 @ 1:25 pm |
I am not sure if I get your point but perhaps:
drop table test_ind_selectivity; create table test_ind_selectivity tablespace test_ts as select rownum id , mod(rownum, 10) col1 , mod(rownum, 100) col2 , mod(rownum, 1000) col3 , lpad('*', 100, '*') pad from dual connect by level <= 100000; exec dbms_stats.gather_table_stats(user, 'TEST_IND_SELECTIVITY', method_opt=>'FOR ALL COLUMNS SIZE 1') create index test_ind_selectivity_ix1 on test_ind_selectivity(col1, col2); create index test_ind_selectivity_ix2 on test_ind_selectivity(col1, col2, col3); select /*+ index(test_ind_selectivity) test1 */ count(id) from test_ind_selectivity where col1 = 1 and col2 = 1; --------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 11 | 1003 (0)| 00:00:06 | | 1 | SORT AGGREGATE | | 1 | 11 | | | | 2 | TABLE ACCESS BY INDEX ROWID| TEST_IND_SELECTIVITY | 1000 | 11000 | 1003 (0)| 00:00:06 | |* 3 | INDEX RANGE SCAN | TEST_IND_SELECTIVITY_IX1 | 1000 | | 3 (0)| 00:00:01 | --------------------------------------------------------------------------------------------------------- alter index test_ind_selectivity_ix1 invisible; select /*+ index(test_ind_selectivity) test1 */ count(id) from test_ind_selectivity where col1 = 1 and col2 = 1; --------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 11 | 102 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 11 | | | | 2 | TABLE ACCESS BY INDEX ROWID| TEST_IND_SELECTIVITY | 100 | 1100 | 102 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | TEST_IND_SELECTIVITY_IX2 | 100 | | 2 (0)| 00:00:01 | ---------------------------------------------------------------------------------------------------------test_ind_selectivity_ix2 makes test_ind_selectivity_ix1 somehow redundant – but when the index is made invisible the optimizer is confused.
Regards
Martin
Comment by Martin Preiss — April 10, 2014 @ 2:12 pm |
Martin,
Thanks a lot.
That’s exaclty what I was refering to.
It’s a great pleasure to see you reading my blog
Best regards
Comment by hourim — April 10, 2014 @ 2:16 pm |
Martin,
It is depending on the number of distinct combinations (distinct_key) the selected index is having on its indexed columns that are present in the query predicate. Using the distinct_key of the first index the CBO is able to find the right number of combination each couple of (col1,col2) might have (100 distinct combinations). And this is why the CBO is able to compute a correct estimation = (total rows / 100 combinations) = 1000.
SQL> with got_col_combination as (select col1 , col2 , count(1) nbr_comb from test_ind_selectivity group by col1 , col2 ) select distinct nbr_comb from got_col_combination; NBR_COMB ---------- 1000 SQL> select index_name, num_rows, distinct_keys, num_rows/distinct_keys estimation 2 from user_indexes where table_name = 'TEST_IND_SELECTIVITY'; INDEX_NAME NUM_ROWS DISTINCT_KEYS ESTIMATION ------------------------------ ---------- ------------- ---------- TEST_IND_SELECTIVITY_IX1 100000 100 1000Using the distinct_key of the second index, the CBO will use the total number of distinct combination of (col1,col2,col3) which is not anymore 100 but 1000; and this is why the CBO is wrongly estimating the number of rows to be returned (total rows / 1000 combinations) = 100 when using the second index (after dropping the first one that has been considered redundant)
SQL> with got_col_combination as (select col1 , col2 , col3 , count(1) nbr_comb from test_ind_selectivity group by col1 , col2 , col3 ) select distinct nbr_comb from got_col_combination; NBR_COMB ---------- 100 SQL> select index_name, num_rows, distinct_keys, num_rows/distinct_keys estimation 2 from user_indexes where table_name = 'TEST_IND_SELECTIVITY'; INDEX_NAME NUM_ROWS DISTINCT_KEYS ESTIMATION ------------------------------ ---------- ------------- ---------- TEST_IND_SELECTIVITY_IX2 100000 1000 100However, when we add col3 to the query the CBO starts doing good estimations
SQL> select /*+ index(test_ind_selectivity) test1 */ count(id) from test_ind_selectivity where col1 = 1 and col2 = 1 and col3 = 1; COUNT(ID) ---------- 100 --------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 101 (100)| | | 1 | SORT AGGREGATE | | 1 | 15 | | | | 2 | TABLE ACCESS BY INDEX ROWID| TEST_IND_SELECTIVITY | 100 | 1500 | 101 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | TEST_IND_SELECTIVITY_IX2 | 100 | | 1 (0)| 00:00:01 | --------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("COL1"=1 AND "COL2"=1 AND "COL3"=1)Best regards
Comment by hourim — April 11, 2014 @ 8:28 am |
[…] Redundant Indexes […]
Pingback by Index design | Mohamed Houri’s Oracle Notes — September 3, 2014 @ 2:56 pm |
[…] birds with one stone” design strategy as far as with one index you can cover multiple queries, avoid redundant indexes and cover the foreign key lock threat. Do not forget the benefit an indexed virtual column could […]
Pingback by Index design: discard and sort – All Things Oracle — October 10, 2014 @ 3:47 pm |